AlphaZero [2018] - история о плодотворной дружбе поиска и глубокого обучения
Обобщая, есть 2 поколения подходов в настольных играх:
1) Поиск по всем вариантам с оптимизациями Шахматные алгоритмы, начиная с появления компьютеров, как минимум до Deep Blue [1997], работали на основе таких подходов. В глубине души они по эффективности похожи на полный перебор, но засчёт хитростей (вроде дебютной книги и эвристических оценок позиций в листьях дерева поиска) алгоритмам удаётся как-то работать.
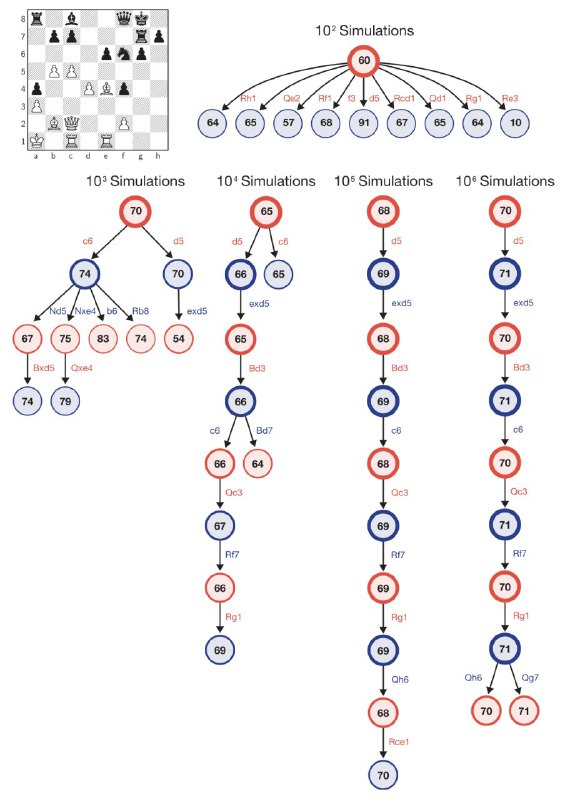
2) Направленный поиск с помощью обучаемой функции полезности Именно в этом и состояла революция AlphaGo (и её потомка AlphaZero). Оказалось, что обучаемая функция полезности действия в данной позиции позволяет перебирать радикально меньше вариантов ходов из каждой позиции. Она позволяет строить дерево поиска на больше ходов вперёд, потому что мы грамотно выбираем ходы при переборе. Что интересно, обучается данная функция довольно просто - достаточно генерировать данные, садя алгоритм играть против себя же и своих прошлых итераций, и учить её предсказывать результат игры. В результате система легко обходит человека в шахматы и го.
Слабые точки AlphaZero понятны - требует много данных, обучается отдельно под одну игру. Но все революции за раз не совершить!
AlphaZero [2018] - история о плодотворной дружбе поиска и глубокого обучения
Обобщая, есть 2 поколения подходов в настольных играх:
1) Поиск по всем вариантам с оптимизациями Шахматные алгоритмы, начиная с появления компьютеров, как минимум до Deep Blue [1997], работали на основе таких подходов. В глубине души они по эффективности похожи на полный перебор, но засчёт хитростей (вроде дебютной книги и эвристических оценок позиций в листьях дерева поиска) алгоритмам удаётся как-то работать.
2) Направленный поиск с помощью обучаемой функции полезности Именно в этом и состояла революция AlphaGo (и её потомка AlphaZero). Оказалось, что обучаемая функция полезности действия в данной позиции позволяет перебирать радикально меньше вариантов ходов из каждой позиции. Она позволяет строить дерево поиска на больше ходов вперёд, потому что мы грамотно выбираем ходы при переборе. Что интересно, обучается данная функция довольно просто - достаточно генерировать данные, садя алгоритм играть против себя же и своих прошлых итераций, и учить её предсказывать результат игры. В результате система легко обходит человека в шахматы и го.
Слабые точки AlphaZero понятны - требует много данных, обучается отдельно под одну игру. Но все революции за раз не совершить!
Durov said on his Telegram channel today that the two and a half year blockchain and crypto project has been put to sleep. Ironically, after leaving Russia because the government wanted his encryption keys to his social media firm, Durov’s cryptocurrency idea lost steam because of a U.S. court. “The technology we created allowed for an open, free, decentralized exchange of value and ideas. TON had the potential to revolutionize how people store and transfer funds and information,” he wrote on his channel. “Unfortunately, a U.S. court stopped TON from happening.”
That growth environment will include rising inflation and interest rates. Those upward shifts naturally accompany healthy growth periods as the demand for resources, products and services rise. Importantly, the Federal Reserve has laid out the rationale for not interfering with that natural growth transition.It's not exactly a fad, but there is a widespread willingness to pay up for a growth story. Classic fundamental analysis takes a back seat. Even negative earnings are ignored. In fact, positive earnings seem to be a limiting measure, producing the question, "Is that all you've got?" The preference is a vision of untold riches when the exciting story plays out as expected.